반응형
- 자연어처리(NLP, Natural Language Processing)
- 자연어처리에서 자료 불충분의 경우 해당과정과 유사한 사전 훈련된 커브넷을 사용할 경우 자신만의 좋은 특성을 학습하지 못하더라도 꽤 일반적인 특성을 재사용하는 것이 합리적이다.
- 일반적 언어Model 처리 순서 : Tokenizer() -> fit_on_text(docs) -> text_to_sequence(docs)
- Deep learning Model 입력할 경우 학습 Data의 크기가 모두 동일해야 하므로Padding 과정이 존재한다.
- Sparsity Problem : 충분한 Data를 관측하지 못하여 언어를 정확히 Modeling하지 못하는 문제
- NLP평가방법
- Perplexity(PPL) : 언어 Model이 특정시점에서 평균적으로 몇 개의 선택지를 가지고 고민하는지를 의미하는 것으로서 값이 낮을수록 좋다.
- Domain에 알맞은 동일한 test data를 사용해야 신뢰도가 높다.
- Word Representation
- 국소표현(Local Representation) : 해당 단어 자체만을 보고 특정값을 매핑하여 단어를 표현하는 방법
- 분산표현(Distributed Representation) : 해당 단어를 표현하고자 주변을 참고하여 단어를 표현하는 방법
반응형

-
- BOW(Bag Of Words)
- 단어 등장의 순서를 고려하지 않은 빈도기반 단어 표현 방법
- 주요 등장 단어 구성에 따라 문서가 어떤 종류의 문서인지 판단하는데 BOW를 사용할 수 있다.
- Ex) 수학단어(미분,적분,항등식…)의 빈도가 높다 ==>>> 수학 관련 문서
- BOW(Bag Of Words)
-
- DTM의 한계
- 희소표현(Sparse Representation) è One-Hot Encoding같이 많은 양의 저장공간과 계산복잡도의 증가
- 단순 빈도수 기반의 접근법
- TF-IDF(Term Frequency – Inverse Document Frequency)
- 단어의 빈도와 역문서빈도를 사용하여 DTM내의 각 단어들마다 중요도를 가중치로 주는 방법
- DTM생성 후TF-IDF를 생성한다.
- Ex) 문서유사도, 검색시스템에서 검색결과의 중요도, 문서 내의 특정 단어의 중요도 구하기 등등 활용
- tf(d, t) : 특정문서 d에서 특정단어 t의 등장 횟수
- df(t) : 특정단어 t가 등장한 문서의 수
- idf : df(t)에 반비례하는 수
- DTM의 한계
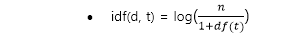
728x90
반응형



