반응형
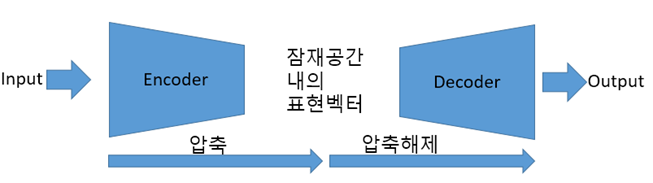
- 오토인코더(AE, AutoEncoder)
- 입력을 저 차원 잠재공간으로 인코딩한 후 디코딩하여 복원하는 작업. 즉, “원본Data를 재구성하는 방법”을 학습
- 원본 Input ==>> Encoder è 입력표현 ==>> Decoder ==>> 재구성된 입력
- 특징을 유추할 수 있는 것들이 모여 이미지를 생성하는 것으로 GAN대비 흐릿하고 초점이 불분명하다
- (영상의학분야 등 같은) 아직 Data가 불충분한 분야에서 Data의 특징을 잘 담아내는 AE경우 부족한 학습 Data 보충에 효과적
- L1규제 for AE – L1규제는 Data의 독립적인 변동성을 포착하지 못하는 경우 매개변수값을 0으로 강제하기 때문에 sparse encoding(희소 인코딩)을 초래하여 더 높은 차원의 숨겨진 레이어가 있는 불완전한 AE라도 신호 내역을 학습할 수 있다.
- 노이즈제거 AE – 원본 Data의 Data생성 과정을 학습하는 것으로 나타났으며, 입력을 발생시키는 확률분포를 학습하는 것이 목표인 생성 Modeling에서 널리 사용된다.
- 입력을 저 차원 잠재공간으로 인코딩한 후 디코딩하여 복원하는 작업. 즉, “원본Data를 재구성하는 방법”을 학습
반응형
- Seq2Seq AE
- 순차적으로 생성된 Data의 특성에 맞게 표현을 학습하는 목표로 개발됨
- LSTM이나 GRU같은 RNN구성요소 기반으로 만들어졌다.
- 변이형 오토인코더(VAE, Variational AutoEncoder)
- 딥러닝과 베이즈추론(Bayesian inference)의 아이디어를 혼합한 AE. 즉, 오토인코더에 약간의 통계기법을 추가하고 연속적이고 구조적인 잠재공간을 학습하도록 만듦(결국 이미지 생성도구)
- 이미지를 어떤 통계분포의 parameter로 변환(=Input Image가 통계적 과정을 통해 생성되었다고 가정하에 인코딩과 디코딩하는 동안 무작위성이 필요하다.) 따라서, VAE는 평균과 분산을 이용하여 무작위 sample을 추출한 뒤 이 샘플을 디코딩하여 원본 Data로 복원하는 것으로 잠재공간에서 샘플링한 모든 point는 유효한 출력으로 디코딩된다.
728x90
반응형
'Data Science & AI Theories' 카테고리의 다른 글
| 적대적생성신경망(GAN, Generative Adversarial Networks) (2) | 2023.08.19 |
|---|---|
| 순환신경망(RNN, Recurrent Neural Network), 장단기메모리(LSTM, Long Short Term Memory), 게이트 순환 유닛(GRU, Gated Recurrent Unit) (1) | 2023.08.18 |
| CNN(컨볼루션 신경망) & 배치 정규화(Batch Normalization) (0) | 2023.08.17 |
| Neural Network(신경망) & Deep Learning(딥러닝) (0) | 2023.08.17 |
| 자연어처리(NLP)(4) - Transformer, Attention (0) | 2023.08.16 |

